递归算法在文档管理系统中可以用于实现多层次的文件结构和对文件目录的遍历、搜索、排序等操作。下面是递归算法在文档管理系统中的几个常见应用:
- 文件树遍历:文档管理系统通常以树形结构组织文件和文件夹。递归算法可以用于遍历整个文件树,从根节点开始逐层遍历子节点,以获取所有文件和文件夹的信息。通过递归遍历,可以构建文件树的完整视图或执行其他针对每个节点的操作。
- 文件搜索:当用户需要搜索特定文件或按特定条件筛选文件时,递归算法可以应用于文件搜索功能。通过递归地遍历文件夹和子文件夹,算法可以在每个节点上检查文件名、属性、内容等,以匹配用户指定的搜索条件并返回符合条件的文件列表。
- 文件排序:文档管理系统通常支持按名称、大小、修改日期等属性对文件进行排序。递归算法可以用于实现这些排序功能。通过递归地遍历文件夹和子文件夹,并根据指定的排序规则对文件进行比较和交换,可以实现整个文件树的排序。
- 文件夹操作:递归算法也可以用于执行针对文件夹的操作,例如复制文件夹及其所有子文件夹、删除文件夹及其所有子文件夹等。通过递归地访问文件夹的子文件夹,并对每个子文件夹执行相同的操作,可以实现对整个文件夹结构的批量操作。
递归算法在文档管理系统中的应用有一些优势,但也存在一些潜在的误区。以下是它们的概述:
优势:
- 灵活性和可扩展性:递归算法可以处理多层次的文件结构,无论文件夹的嵌套层次有多深。这种灵活性使得文档管理系统可以应对各种复杂的文件组织方式,并能够适应未来的扩展需求。
- 代码简洁性:递归算法通常具有简洁、优雅的代码结构。通过递归调用函数自身,可以简化对文件夹结构的遍历、搜索和操作等操作的实现,减少代码量和复杂性。
- 逻辑清晰性:递归算法能够自然地表达文件夹结构的逻辑。通过递归调用,可以将文件夹的层次结构映射到算法的递归调用过程中,使得代码更易于理解和维护。
误区:
- 潜在的性能问题:递归算法在处理大型文件系统或深层次的文件结构时可能面临性能问题。每次递归调用都需要额外的函数调用和堆栈空间,可能导致内存消耗较大,并且在某些情况下可能导致堆栈溢出。在实际应用中,需要仔细评估和优化递归算法的性能。
- 无限循环的风险:递归算法的一个常见问题是潜在的无限循环风险。如果没有正确定义递归的终止条件或处理递归中的边界情况,就可能陷入无限循环的情况,导致系统崩溃或无法正常工作。
- 可能的资源浪费:由于递归算法涉及多次函数调用和数据传递,可能会导致一些不必要的资源浪费。例如,在某些情况下,通过迭代或其他非递归方法可能更有效地完成相同的任务。
因此,在应用递归算法时,需要注意性能问题、循环控制和资源利用等方面,并进行适当的优化和测试,以确保系统的稳定性和效率。
关于TeamDoc软件:
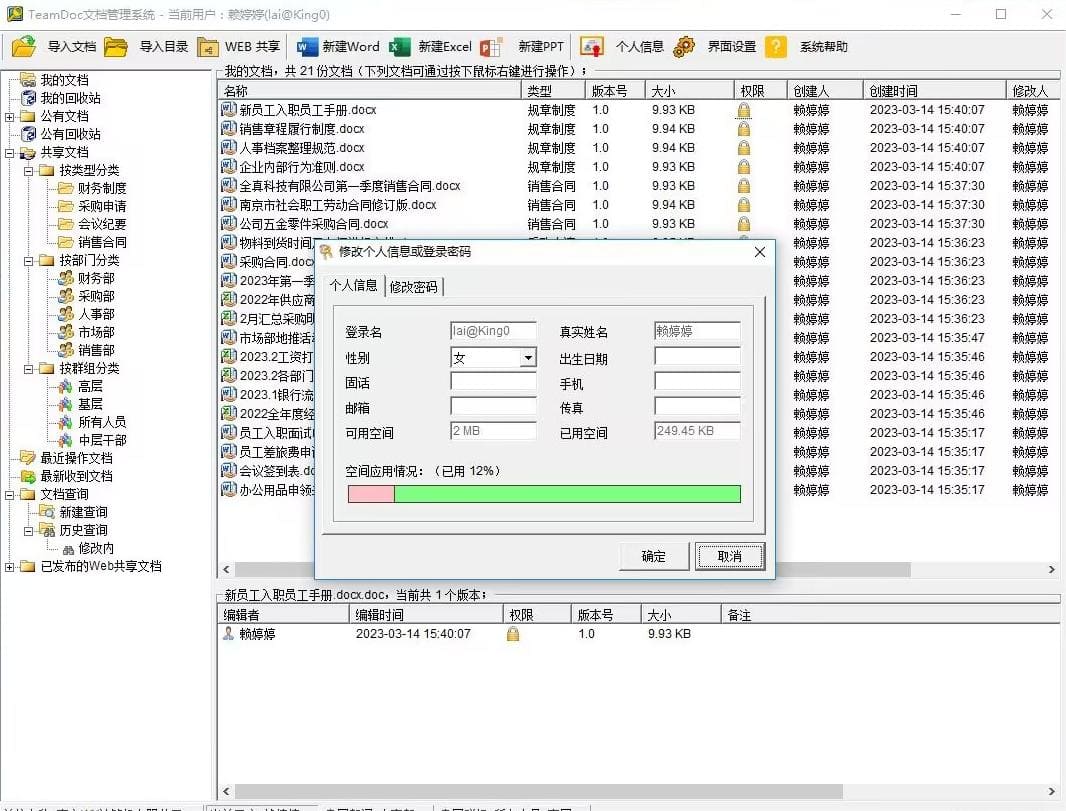
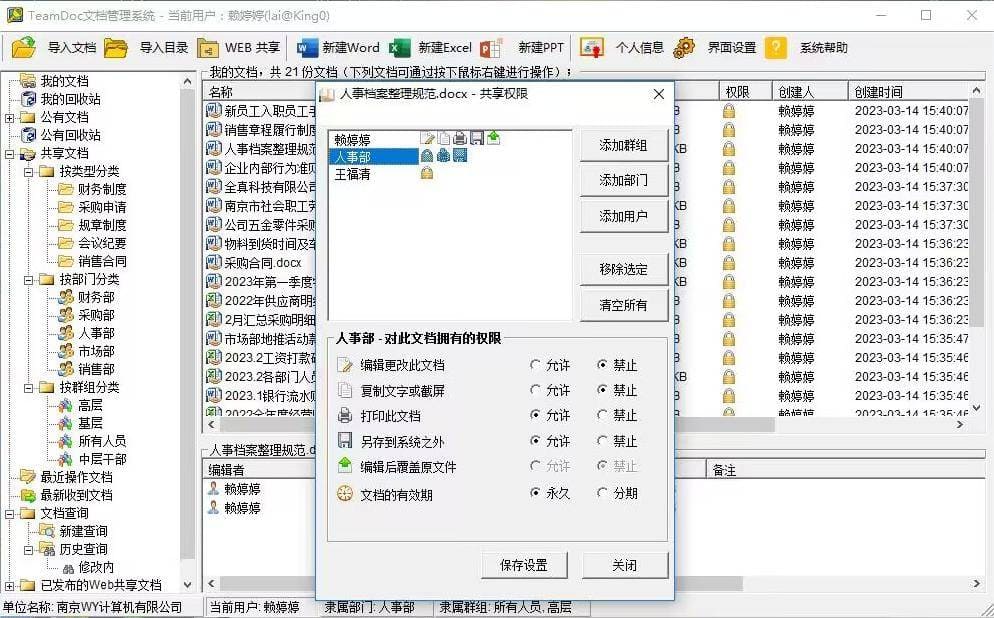
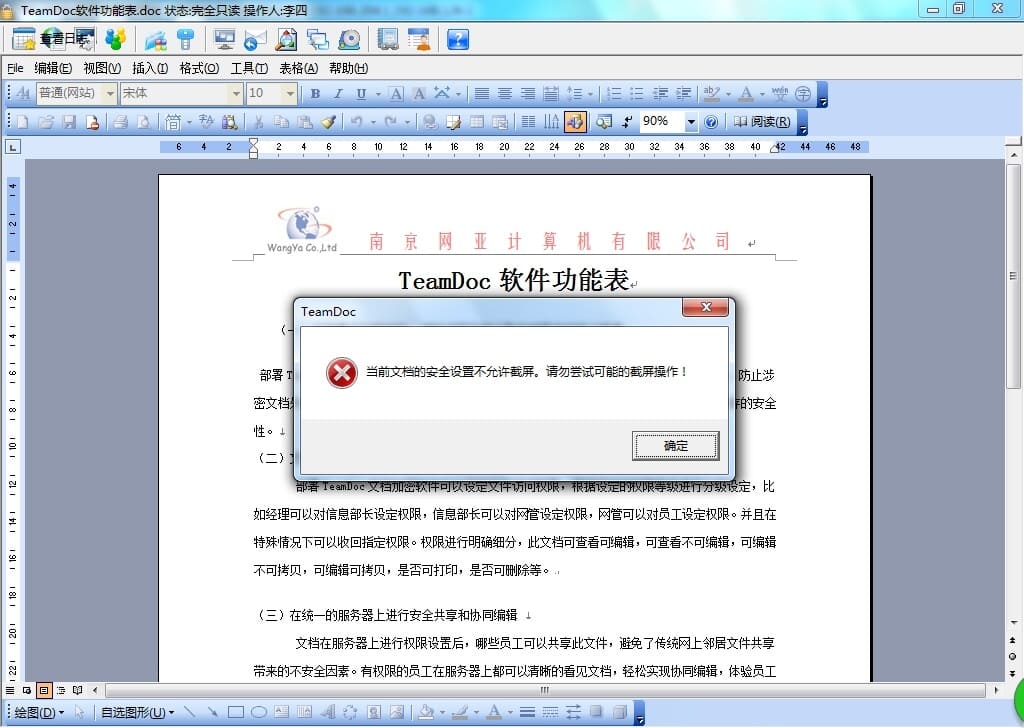
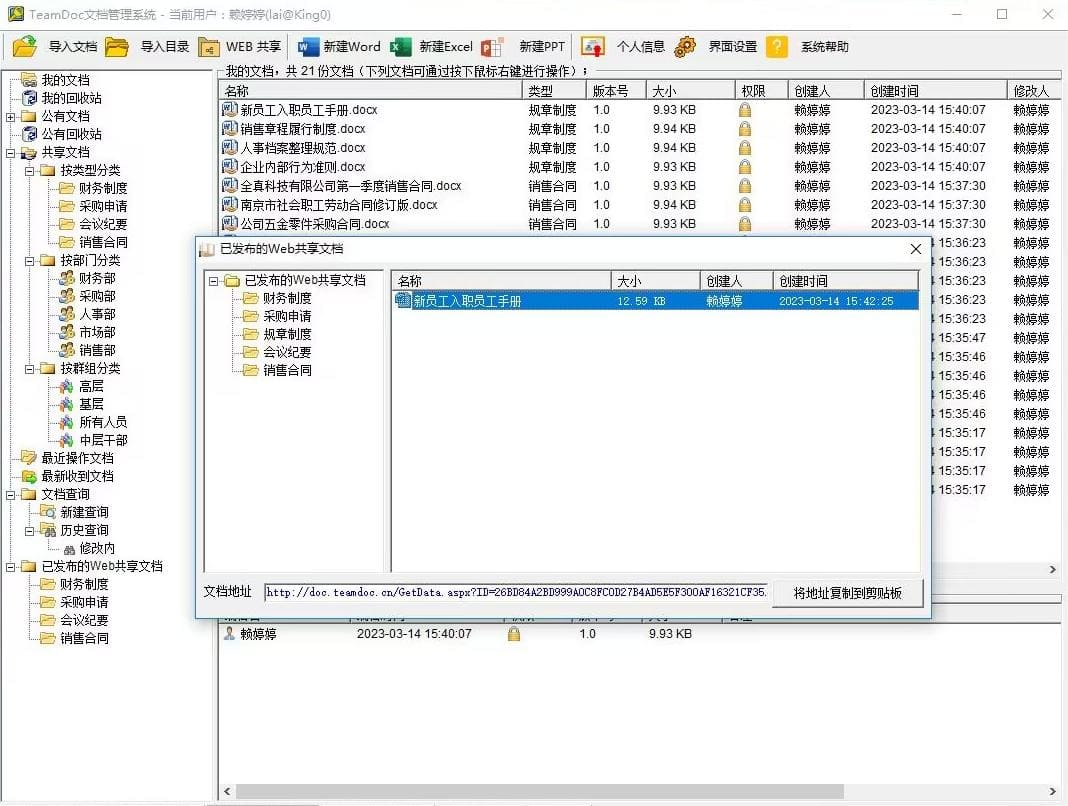
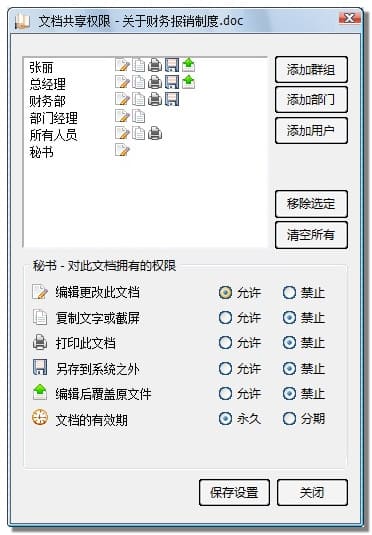
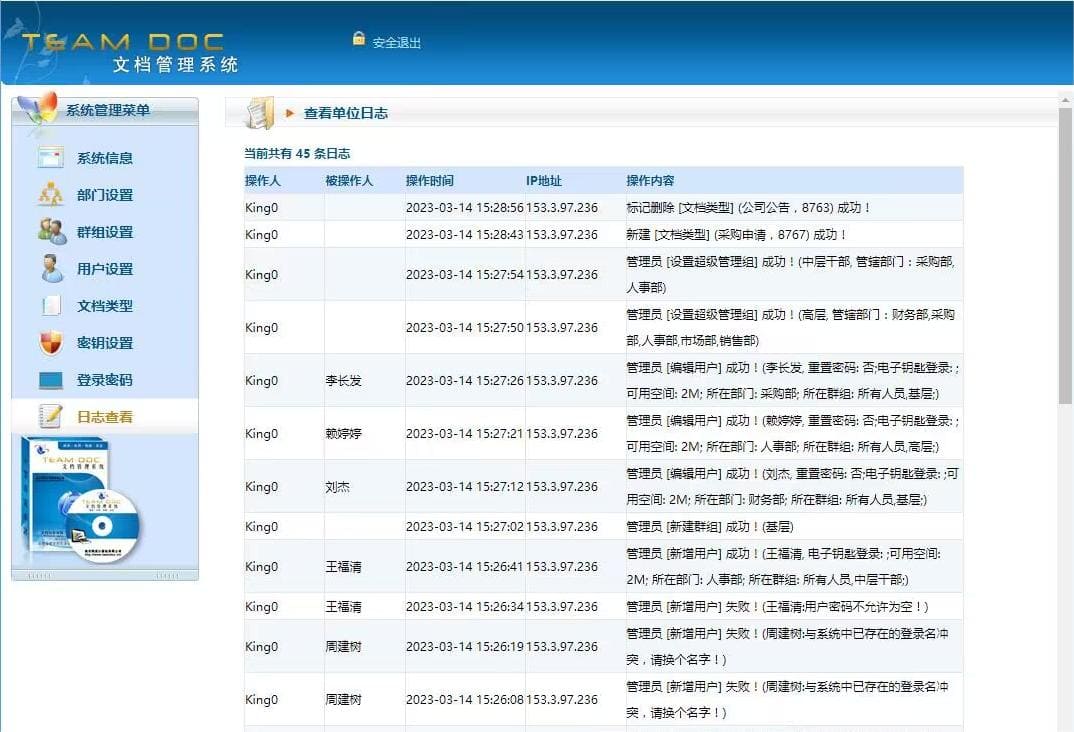
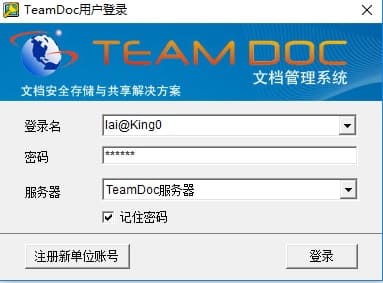
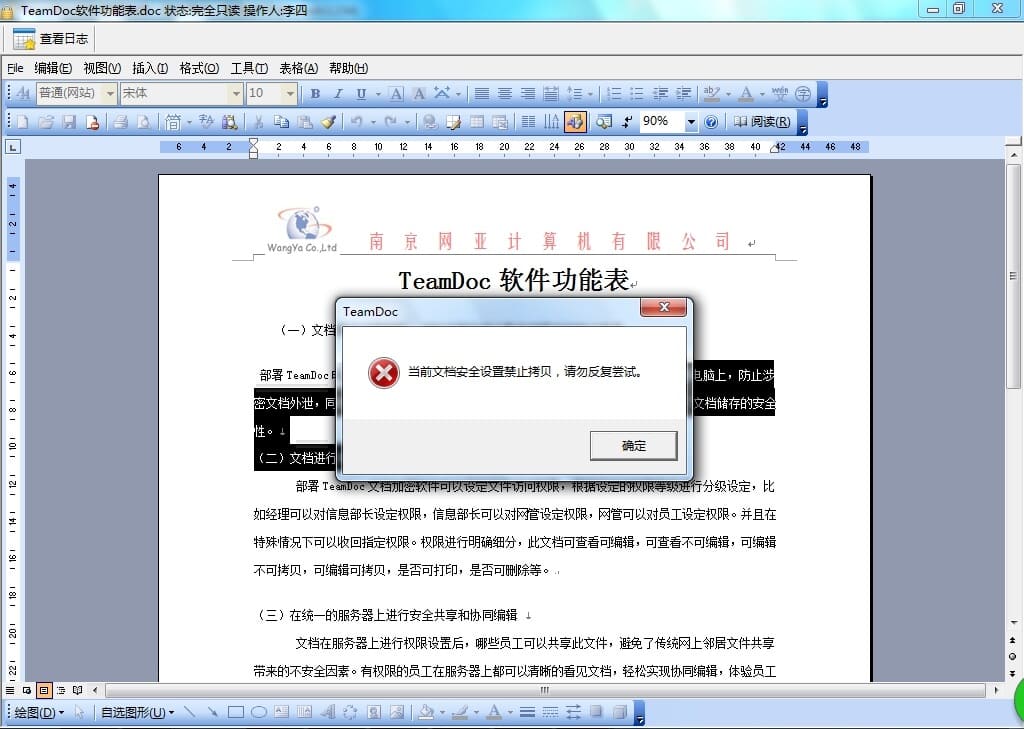
TeamDoc是基于服务器/客户端架构的轻量级文件管理软件。TeamDoc将文件集中加密存储在您单位自己的服务器中,员工使用TeamDoc客户端访问服务器,从而获得与自己权限相关的权限:登入后与“我的电脑”界面类似,可以看到自己该看的文件,编辑自己能编辑的文档,对于能看到的文件,还可以细分文档权限,进而做到能看不能拷,能看不能截屏等功能,多种权限灵活设置,在线协同编辑、全文搜索、日志与版本追踪,快速构建企业文档库。告别假大空,我们提供值得您选择的、易用的、可用的文档管理软件。现在就访问TeamDoc首页
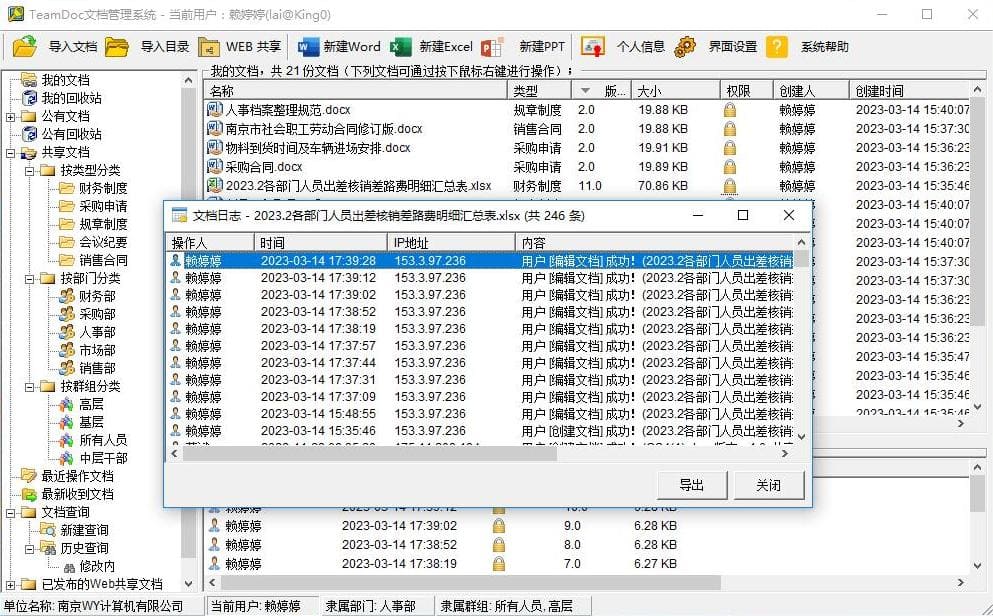
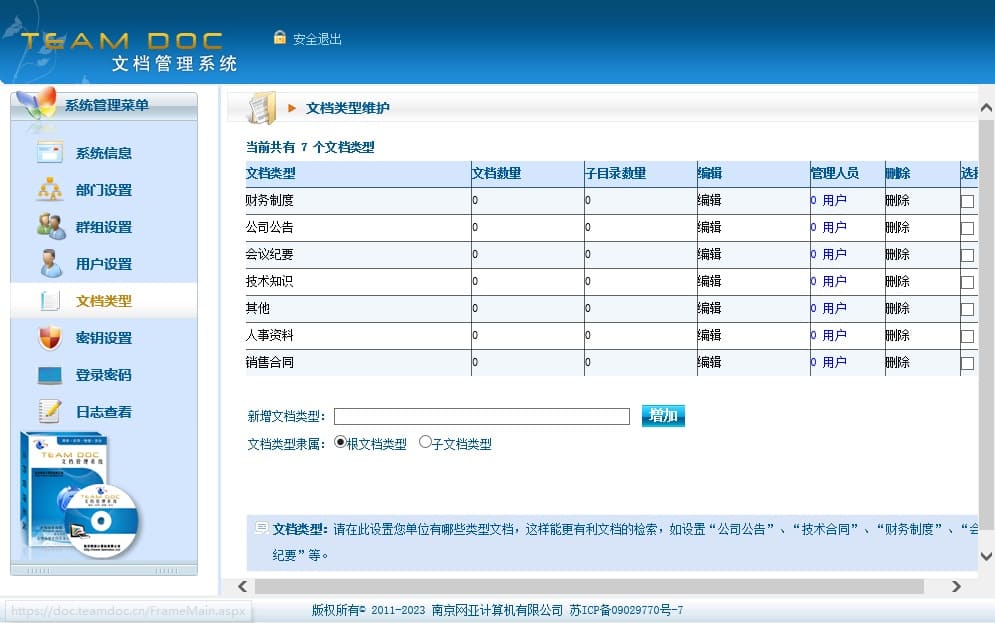
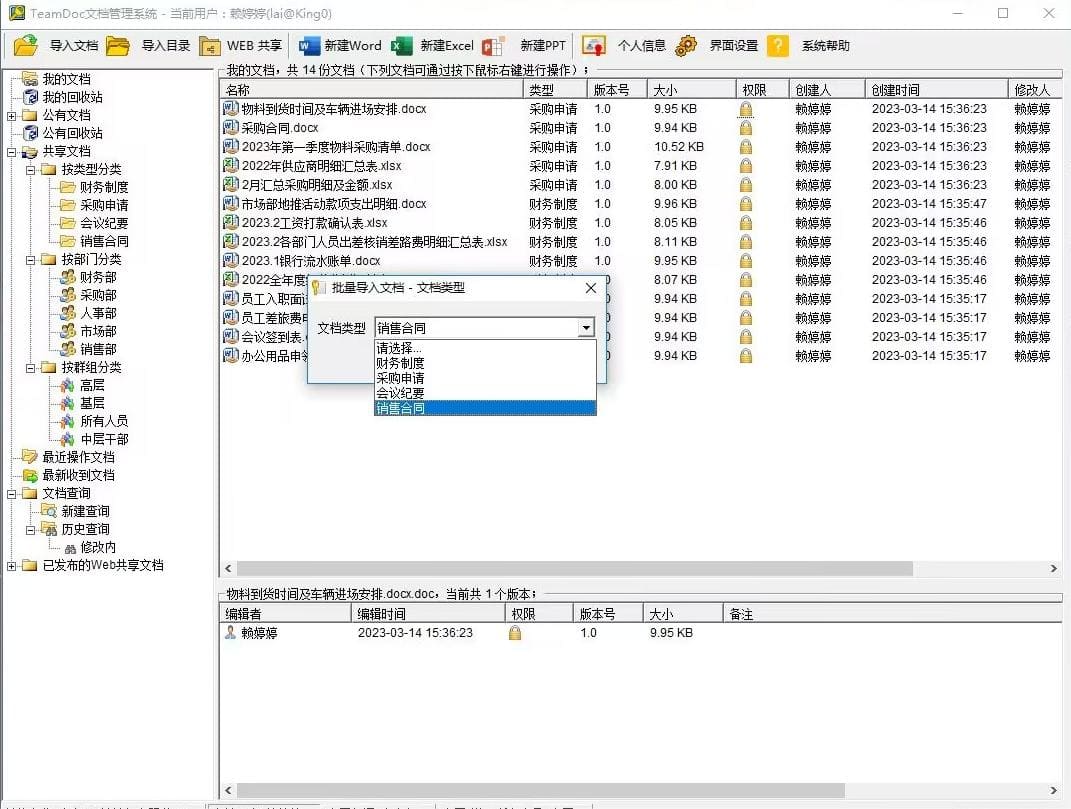
TeamDoc软件界面(点击可放大)


版权所有:南京网亚计算机有限公司,本文链接地址: 递归算法在文档管理系统中的运用、优势以及可能的误区